这是我自用的一个简单的python小脚本,用来翻译ftbquests中的任务文件。其实就是正则表达式摘取snbt中指定内容加api翻译,如果你是大佬看个乐就行。自己拿来跑双语机翻任务,游玩国外整合包还是蛮方便的。
希望大家不要把机翻出来的任务文件未经修整直接发布,粗劣机翻会影响他人游玩体验。
想必接触过任务汉化的应该都知道ftbquest中任务文件大多存储在config下的ftbquest文件夹中。
其中的chapters以及rewardtables文件夹下分别存储着子章节任务以及所有奖励表,除此之外也可能有章节集合chapter_groups.snbt以及任务整体信息data.snbt等文本,但不论文件类型如何他们所需翻译的区域是相同的即title、subtitle、description、text这几个可能存在的区域,我们只需要专注于这些内容摘出其中文本送给api翻译即可。
一个常规的chapter下子任务snbt内容
{
title: "A Real Improvement to your ME Network",
x: 1.0d,
y: -1.0d,
description: "Let's use P2P Tunnel's!",
text: [
"It is §chard§f to §2explain in details§f about a §6P2P Setup§f here, but here's a rough explanation:",
"",
"- With §62 P2P Tunnel's§f, you can link them using a §dMemory Card§f.",
"",
"- §9One§f of them §8§o(the first you've clicked)§r§f will be the §9Input§f and the §bother§f one will be the §bOutput§f.",
"",
"- With §5Between§f these §62 P2P's§f there §dwill be a Subnetwork formed§f, meaning, that you'll need to §eprovide it with Power§f.",
"§8§o(You could use an Energy Acceptor or a Quartz Fiber to route Energy from your Main Network)§r§f",
"",
"- This could be §aREALLY§f good to get §d32 Channels§f from your §3Main AE Network§f from §9point A§f to §epoint B§f across a §dsubnetwork§f.",
"",
"- §aA Good AE2 Engineer§f really §3takes advantage of this feature§f, as once you've learn how to use it, §c§nChannel's will never be a problem anymore§r§f.",
"",
"§8§o~ Please, for more Information, check the next quest for a link to the Official Wiki.§r§f"
],
dependencies: [
"e54b21e4"
],
min_width: 300,
tasks: [{
uid: "692d8d75",
type: "item",
items: [{
item: "appliedenergistics2:part 1 460"
}],
count: 2L
},
{
uid: "fdaeca22",
type: "item",
items: [{
id: "appliedenergistics2:memory_card",
tag: {}
}],
ignore_damage: true,
ignore_nbt: 1b
}],
rewards: [{
uid: "da1219ea",
type: "ftbmoney:money",
ftb_money: 50L
}]
}代码
#本项目将于github持续更新完善,以下代码非最新但整体思路不变。
#本脚本更替思路受项目https://github.com/djacu/ftbquests_converter启发,并在其框架基础上进行了大量更新与优化,对标当前最新ftbquest的任务生成格式
from hashlib import md5
from pathlib import Path
import re
import random
from typing import Tuple
import requests
def get_text_fields(quest: str) -> Tuple[str]:
'''
截取翻译区域
:param quest: 任务文本
:return: 截取到的title,subtitle,description,text文本指针
'''
title_line=re.findall(r'\stitle: "(.*)"', quest)
subtitle_line=re.findall(r'\ssubtitle: "(.*)"', quest)
# decription_search = re.search(r'\sdescription: \[\n([^]]*)\]', quest)
# decription_lines = re.findall(r'"(.+)"', decription_search.group(1)) if decription_search else ()#去掉双引号
decription_lines=re.findall(r'\sdescription: \[[\n]*([^]]*)\]', quest)#先指定以关键字打头,再进一步匹配到左括号略过换行再截取所有右括号前字符,下同
decription_lines=[re.findall(r'"(.+)"', x) for x in decription_lines]
decription_lines=[token for t in decription_lines for token in t]#双层遍历降维
text_search = re.search(r'\stext: \[[\n]*([^]]*)\]', quest)
text_lines = re.findall(r'"(.+)"', text_search.group(1)) if text_search else ()
return (*title_line, *subtitle_line, *decription_lines, *text_lines)
def translate_line(line: str) -> str:
'''
翻译送来的字符串
:param line:字符串
:return:翻译结果字符串
'''
try:
# 关于语言选项参考文档 `https://api.fanyi.baidu.com/doc/21`
# 百度appid/appkey.(PS:密钥随IP绑定,设置密钥时候注意设置正确的IP否则无法使用!!!)
appid = '20211231001043264' # 请注册你自己的密钥
appkey = 'umhmUOazS1sa9xMK6fzR' # 请注册你自己的密钥
from_lang = 'en'
to_lang = 'zh'
endpoint = 'http://api.fanyi.baidu.com'
path = '/api/trans/vip/translate'
url = endpoint + path
def make_md5(s, encoding='utf-8'):
return md5(s.encode(encoding)).hexdigest()
salt = random.randint(32768, 65536)
sign = make_md5(appid + line + str(salt) + appkey)
# Build request
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {'appid': appid, 'q': line, 'from': from_lang, 'to': to_lang, 'salt': salt,
'sign': sign, 'action': 1}
# Send request
r = requests.post(url, params=payload, headers=headers)
result = r.json()
return result.get('trans_result')[0].get('dst')
except TypeError:
'''
TypeError: 'NoneType' object is not subscriptable
八成是appid和appkey不正确或申请的服务中绑定的IP设置错误,小概率网络波动原因
'''
print("api调用出错")
return line
#return translate_line(line)
def update_quest(quest: str, text_fields: Tuple[str]) -> str:
'''
更新任务中需要汉化的区域
:param quest:任务
:param text_fields:摘取出的替换文本
:return:汉化后任务
'''
for line in text_fields:
##情景1:图片介绍
if ( line.find('.jpg')==-1 and line.find('.png'))==-1: # 新版ftbquest可以展示图片,遇到图片则略过
## 情景2:彩色区域
# 彩色格式保留,碰到&.彩色格式在后方则加入空格分割来辅助百度api优化翻译效果(比如Hello &5world改为Hello &5 world)
# 强烈建议在术语库中手动添加术语保留&.,否则可能文本格式错误。(目前已知的彩色格式只有a~f,0~9全部依次录入即可)百度api大多可以返回包含&.的汉化结果。
findDec = line.find('&') # 确定有无彩色标签(-1无,非-1有)
if (findDec != -1):
t = 1
all_index = [r.span() for r in re.finditer('&', line)] # 记录&出现的所有位置
tmp = list(line)
for i in all_index:
tmp.insert(i[1] + t, ' ')
t = t + 1 # 由于前面的空格增加会改变目录顺序,这里做出修正
colored_line = ''.join(tmp)
print("检测到包含彩色标识的任务,处理为" + colored_line)
##情景3:物品引用
# 比如#minecraft:coals需要保留,打破此格式将会导致此章任务无法读取!!!
# 这里给出的方案是先将引用替换为临时词‘xdawned’,术语库中设置xdawned-xdawned来保留此关键词,然后借此在翻译后的句子中定位xdawned用先前引用词换回
translate= translate_line(re.sub(r'#([^[\n|\|\s"]*)', 'xdawned' , colored_line))
else:
translate= translate_line(re.sub(r'#([^[\n|\|\s"]*)', 'xdawned' , line))
#将物品引用换回
quotes=re.findall(r'#([^[\n|\|\s"]*)', line)#找出所有引用词
if len(quotes)>0:
print('在此行找到引用',quotes)
count=0
#找出xdawned出现的所有位置并替换为对应引用词
index=translate.find('xdawned')
while index!=-1:
translate=re.sub('xdawned',quotes[count],translate,1)
count=count+1
index = translate.find('xdawned')
print(translate)
replacement = translate + "[--" + line + "--]" # 原文保留
print("替换中:" + replacement)
quest = quest.replace('\"' + line + '\"','\"' + replacement + '\"') # 用双引号卡一下因为多处文本可能相同,防止重复替换替换到其它位置;处理过的就为 "原文[--*--]" 不再参与替换
return quest
def update_quest_file(input_path: Path, output_path: Path) -> None:
'''
更新文件,将处理完的文本写回
:param input_path:输入目录
:param output_path:输输出目录
:return:无
'''
with open(input_path, 'r', encoding="utf-8") as fin:
quest = fin.read()
text_fields = get_text_fields(quest)#截取翻译内容
if not text_fields:
print(f'无需翻译,未找到截取关键词 {input_path}.')
print(quest)
else:
print(f'开始翻译 {input_path}.')
new_text = update_quest(quest, text_fields)
with open(output_path, 'w', encoding="utf-8") as fout:
fout.write(new_text)
def make_output_path(path: Path) -> Path:
'''
生成输出目录,为原文件夹+trans
:param path:输入目录路径
:return:自动生成的输出目录路径
'''
parts = list(path.parts)
parts[0] = parts[0] + "-trans"
output_path = Path(*parts)
output_path.parent.mkdir(parents=True, exist_ok=True)
return output_path
def main():
quest_path = Path("./ftbquests")#要翻译的目录【可选./ftbquests或./chapter,./chapter只翻译章节内容,./ftbquests额外包括战利品表名称、大章节标题等内容】
for input_path in quest_path.rglob("*.snbt"):
output_path = make_output_path(input_path)#生成输出目录路径
update_quest_file(input_path, output_path)#更新任务文件
if __name__ == '__main__':
main()#需要先在translate_line函数中填入百度api密钥
使用说明
Ⅰ.创建.py文件并将完整代码粘入
首先你要明白,这只是一段简单的python小程序,需要你随便找一个诸如pycharm,vscode之类的平台创建python项目,将此代码粘进去运行.py文件或者提前导好依赖直接cmd调用也行
(PS:相信这一步可以劝退很多人...,笔者一番下来还是觉得百度的最好用,术语库功能有一些用的可以规避诸如vanilla-香草、chest-胸部之类的经典错误,当然了你也可以自己改动代码,改用其它免费翻译api,但是这些api可能不支持字符&的自动剔除,你可能需要手动将文本中彩色格式标签先剔除,一些免费翻译api)
申请通用翻译api即可,申请成功后可以在开发者信息中找到你的appid和appkey,将代码translate_line函数中的appid和appkey修改掉,千万别忘了绑定你运行此程序的设备网络IP点击查看IP
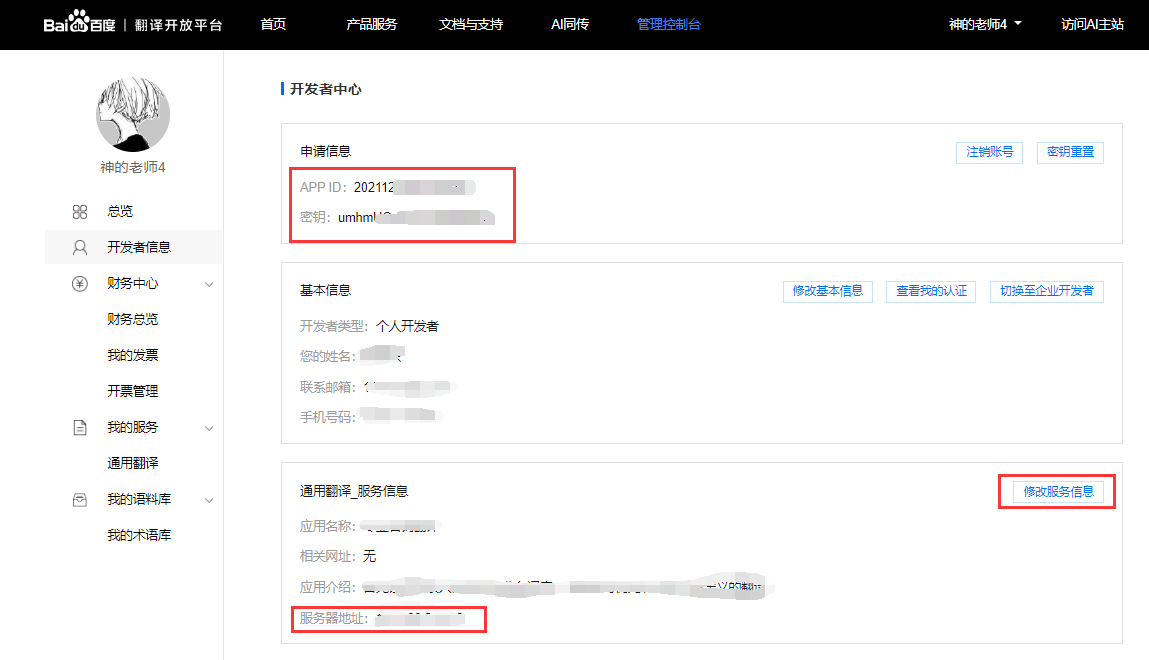
如果你运行程序报错TypeError: 'NoneType' object is not subscriptable那八成就是你的appid和appkey不正确或者申请的服务中绑定的IP设置错误,另外注意你每次重新连接网络路由器为你分配的IP都有可能会变,记得去百度翻译api切换绑定的IP
Ⅲ.安置ftbquest文件
将从config中复制出来的ftbquest分别复制到.py程序同级目录
可能遇到的报错:毕竟是自己写的的snbt读取,虽然我已经试验了大部分的整合包任务但仍然可能代码考虑到的摘取条件不全。如果有能力你可以看情况自行添加额外的过滤,或者在出错后联系我,如果确实是snbt读取错误我会扩充过滤情景并告诉你处理方案。
下面直接运行脚本即可,你可以在编译器中观察到翻译的走向,翻译结果将放在ftbquest-trans文件夹下.
以上所有代码需遵从AGPL-3.0协议


文章评论
GG太强辣!

6啊秀的!